---
title: "Metastability"
date: "2026-01-21"
categories: [distributed systems, simulation]
draft: false
---
This example demonstrates metastability caused by client retries using discrete event simulation powered by [happy-simulator](https://github.com/adamfilli/happy-simulator).
The demonstration is (probably) the simplest possible example of metastability: sustained degradation due to retries due to timeouts due to queue wait times.
## Metastability
```
┌─────────────────────────────────────────────────────────────────────┐
│ METASTABLE FEEDBACK LOOP │
└─────────────────────────────────────────────────────────────────────┘
External Load
│
▼
┌──────────────────┐
│ Total Load │◄─────────────────┐
│ (external+retry) │ │
└────────┬─────────┘ │
│ │
▼ │
┌──────────────────┐ │
│ Queue Depth │ │
│ Increases │ │
└────────┬─────────┘ │
│ │
▼ │
┌──────────────────┐ │
│ Latency │ │
│ Increases │ │
└────────┬─────────┘ │
│ │
▼ │
┌──────────────────┐ ┌───────┴───────┐
│ Timeouts │────────►│ Retries │
│ Increase │ │ Add Load │
└──────────────────┘ └───────────────┘
```
## Load Profile
```
Rate (req/s)
20 │ ╭────────╮
│ │ │ SEVERE SPIKE (200%)
│ │ │
10 │──────────────┤────────│────────────────────────────────
│ Capacity │ │
9 │ ╭──────────┤ ├──────────────╮
│ │ │ │ │
7 │ │ │ │ ╰──────╮
│ │ (90%) │ │ Return to │ ╰──────╮
5 │ │ │ │ 90% │ Step ╰─────────
3 │ │ │ │ │ down
0 └───┴──────────┴────────┴──────────────┴─────────────────→ Time(s)
0 5 20 30 60 75 90 100
Phase 1 (0-20s): High utilization 9 req/s (90% utilization)
Phase 2 (20-30s): SPIKE to 20 req/s (200% - severe overload)
Phase 3 (30-60s): Return to 9 req/s - BUT retries prevent recovery!
Phase 4 (60-75s): Step down to 7 req/s (70%) - may still be stuck
Phase 5 (75-90s): Step down to 5 req/s (50%) - should recover
Phase 6 (90-100s): Step down to 3 req/s (30%) - definitely recovers
```
## Running the Simulation
```{python}
#| code-fold: true
#| code-summary: "Simulation code"
import random
from collections import defaultdict
from dataclasses import dataclass
from typing import Generator
from happysimulator import (
ConstantArrivalTimeProvider,
Data,
Duration,
Entity,
Event,
EventProvider,
FIFOQueue,
Instant,
Probe,
Profile,
QueuedResource,
Simulation,
Source,
)
@dataclass(frozen=True)
class MetastableLoadProfile(Profile):
"""Load profile designed to trigger metastable failure."""
spike_start: float = 20.0
spike_end: float = 30.0
step_down_1_start: float = 60.0
step_down_2_start: float = 75.0
step_down_3_start: float = 90.0
moderate_rate: float = 9.0
spike_rate: float = 20.0
step_down_1_rate: float = 7.0
step_down_2_rate: float = 5.0
step_down_3_rate: float = 3.0
def get_rate(self, time: Instant) -> float:
t = time.to_seconds()
if t < self.spike_start:
return self.moderate_rate
if t < self.spike_end:
return self.spike_rate
if t < self.step_down_1_start:
return self.moderate_rate
if t < self.step_down_2_start:
return self.step_down_1_rate
if t < self.step_down_3_start:
return self.step_down_2_rate
return self.step_down_3_rate
class QueuedServer(QueuedResource):
"""A queued server with exponential service times."""
def __init__(self, name: str, *, mean_service_time_s: float = 0.1, concurrency: int = 1):
super().__init__(name, policy=FIFOQueue())
self.mean_service_time_s = mean_service_time_s
self.concurrency = concurrency
self._in_flight: int = 0
self.stats_processed: int = 0
self.completion_times: list[Instant] = []
self.service_times_s: list[float] = []
def has_capacity(self) -> bool:
return self._in_flight < self.concurrency
def handle_queued_event(self, event: Event) -> Generator[float, None, list[Event]]:
self._in_flight += 1
service_time = random.expovariate(1.0 / self.mean_service_time_s)
yield service_time, None
self._in_flight -= 1
self.stats_processed += 1
self.completion_times.append(self.now)
self.service_times_s.append(service_time)
client: Entity = event.context.get("client")
if client is None:
return []
completion = Event(
time=self.now,
event_type="Completion",
target=client,
context={
"request_id": event.context.get("request_id"),
"original_created_at": event.context.get("created_at"),
"service_time_s": service_time,
},
)
return [completion]
@dataclass
class InFlightRequest:
request_id: int
created_at: Instant
attempt: int
timeout_event_id: int
class RetryingClient(Entity):
"""Client that sends requests with timeout-based retries."""
def __init__(self, name: str, *, server: Entity, timeout_s: float = 0.5, max_retries: int = 5):
super().__init__(name)
self.server = server
self.timeout_s = timeout_s
self.max_retries = max_retries
self._in_flight: dict[int, InFlightRequest] = {}
self._next_timeout_id: int = 0
self.stats_requests_received: int = 0
self.stats_attempts_sent: int = 0
self.stats_completions: int = 0
self.stats_timeouts: int = 0
self.stats_retries: int = 0
self.stats_gave_up: int = 0
self.completion_times: list[Instant] = []
self.latencies_s: list[float] = []
self.attempts_per_request: list[int] = []
self.timeout_times: list[Instant] = []
self.retry_times: list[Instant] = []
def latency_time_series_seconds(self) -> tuple[list[float], list[float]]:
return [t.to_seconds() for t in self.completion_times], list(self.latencies_s)
def goodput_time_series(self, bucket_size_s: float = 1.0) -> tuple[list[float], list[int]]:
if not self.completion_times:
return [], []
buckets: dict[int, int] = defaultdict(int)
for t in self.completion_times:
bucket = int(t.to_seconds() / bucket_size_s)
buckets[bucket] += 1
sorted_buckets = sorted(buckets.keys())
return [b * bucket_size_s for b in sorted_buckets], [buckets[b] for b in sorted_buckets]
def timeout_time_series(self, bucket_size_s: float = 1.0) -> tuple[list[float], list[int]]:
if not self.timeout_times:
return [], []
buckets: dict[int, int] = defaultdict(int)
for t in self.timeout_times:
bucket = int(t.to_seconds() / bucket_size_s)
buckets[bucket] += 1
sorted_buckets = sorted(buckets.keys())
return [b * bucket_size_s for b in sorted_buckets], [buckets[b] for b in sorted_buckets]
def retry_time_series(self, bucket_size_s: float = 1.0) -> tuple[list[float], list[int]]:
if not self.retry_times:
return [], []
buckets: dict[int, int] = defaultdict(int)
for t in self.retry_times:
bucket = int(t.to_seconds() / bucket_size_s)
buckets[bucket] += 1
sorted_buckets = sorted(buckets.keys())
return [b * bucket_size_s for b in sorted_buckets], [buckets[b] for b in sorted_buckets]
def handle_event(self, event: Event) -> list[Event]:
event_type = event.event_type
if event_type == "NewRequest":
return self._handle_new_request(event)
elif event_type == "Completion":
return self._handle_completion(event)
elif event_type == "Timeout":
return self._handle_timeout(event)
return []
def _handle_new_request(self, event: Event) -> list[Event]:
self.stats_requests_received += 1
request_id = event.context.get("request_id", self.stats_requests_received)
return self._send_request(request_id, event.time, attempt=1)
def _send_request(self, request_id: int, created_at: Instant, attempt: int) -> list[Event]:
self.stats_attempts_sent += 1
self._next_timeout_id += 1
timeout_id = self._next_timeout_id
self._in_flight[request_id] = InFlightRequest(
request_id=request_id,
created_at=created_at,
attempt=attempt,
timeout_event_id=timeout_id,
)
server_request = Event(
time=self.now,
event_type="Request",
target=self.server,
context={
"request_id": request_id,
"created_at": created_at,
"attempt": attempt,
"client": self,
},
)
timeout_event = Event(
time=self.now + Duration.from_seconds(self.timeout_s),
event_type="Timeout",
target=self,
context={"request_id": request_id, "timeout_id": timeout_id},
)
return [server_request, timeout_event]
def _handle_completion(self, event: Event) -> list[Event]:
request_id = event.context.get("request_id")
if request_id not in self._in_flight:
return []
in_flight = self._in_flight.pop(request_id)
self.stats_completions += 1
original_created_at = event.context.get("original_created_at", in_flight.created_at)
latency_s = (event.time - original_created_at).to_seconds()
self.completion_times.append(event.time)
self.latencies_s.append(latency_s)
self.attempts_per_request.append(in_flight.attempt)
return []
def _handle_timeout(self, event: Event) -> list[Event]:
request_id = event.context.get("request_id")
timeout_id = event.context.get("timeout_id")
if request_id not in self._in_flight:
return []
in_flight = self._in_flight[request_id]
if in_flight.timeout_event_id != timeout_id:
return []
self.stats_timeouts += 1
self.timeout_times.append(event.time)
del self._in_flight[request_id]
if in_flight.attempt >= self.max_retries:
self.stats_gave_up += 1
return []
self.stats_retries += 1
self.retry_times.append(event.time)
return self._send_request(request_id, in_flight.created_at, attempt=in_flight.attempt + 1)
class ClientRequestProvider(EventProvider):
def __init__(self, client: RetryingClient, *, stop_after: Instant | None = None):
self._client = client
self._stop_after = stop_after
self._request_id: int = 0
def get_events(self, time: Instant) -> list[Event]:
if self._stop_after is not None and time > self._stop_after:
return []
self._request_id += 1
return [
Event(
time=time,
event_type="NewRequest",
target=self._client,
context={"request_id": self._request_id},
)
]
@dataclass
class SimulationResult:
client: RetryingClient
server: QueuedServer
queue_depth_data: Data
requests_generated: int
profile: MetastableLoadProfile
def run_metastable_simulation(
*,
duration_s: float = 100.0,
drain_s: float = 10.0,
mean_service_time_s: float = 0.1,
timeout_s: float = 0.5,
max_retries: int = 5,
probe_interval_s: float = 0.1,
seed: int | None = 42,
) -> SimulationResult:
if seed is not None:
random.seed(seed)
server = QueuedServer(name="Server", mean_service_time_s=mean_service_time_s)
client = RetryingClient(name="Client", server=server, timeout_s=timeout_s, max_retries=max_retries)
queue_depth_data = Data()
queue_probe = Probe(
target=server,
metric="depth",
data=queue_depth_data,
interval=probe_interval_s,
start_time=Instant.Epoch,
)
profile = MetastableLoadProfile()
stop_after = Instant.from_seconds(duration_s)
provider = ClientRequestProvider(client, stop_after=stop_after)
arrival = ConstantArrivalTimeProvider(profile, start_time=Instant.Epoch)
source = Source(name="Source", event_provider=provider, arrival_time_provider=arrival)
sim = Simulation(
start_time=Instant.Epoch,
end_time=Instant.from_seconds(duration_s + drain_s),
sources=[source],
entities=[client, server],
probes=[queue_probe],
)
sim.run()
return SimulationResult(
client=client,
server=server,
queue_depth_data=queue_depth_data,
requests_generated=provider._request_id,
profile=profile,
)
# Run the simulation
result = run_metastable_simulation()
```
## Results
```{python}
#| echo: false
import matplotlib.pyplot as plt
from collections import defaultdict
client = result.client
server = result.server
profile = result.profile
spike_start = profile.spike_start
spike_end = profile.spike_end
step1 = profile.step_down_1_start
step2 = profile.step_down_2_start
step3 = profile.step_down_3_start
```
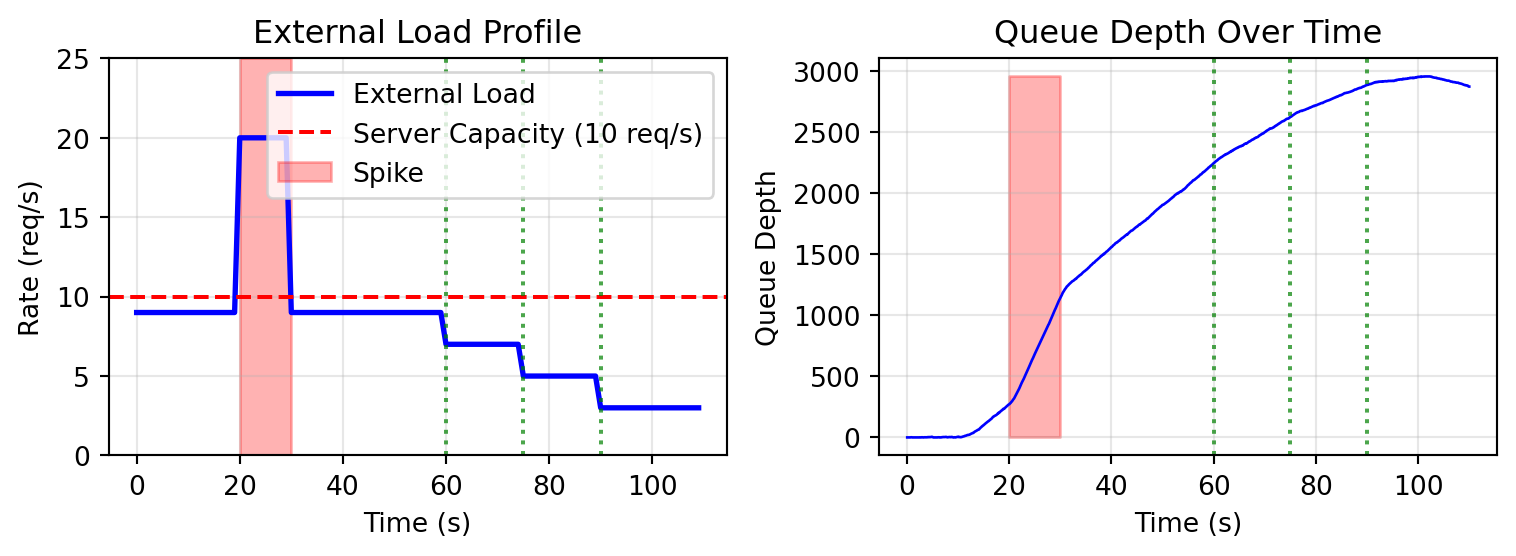
### Load Profile and Queue Depth
```{python}
#| echo: false
fig, axes = plt.subplots(1, 2, figsize=(8, 3))
# Load profile
ax = axes[0]
time_points = list(range(0, 110))
rates = [profile.get_rate(Instant.from_seconds(t)) for t in time_points]
ax.plot(time_points, rates, 'b-', linewidth=2, label='External Load')
ax.axhline(y=10, color='r', linestyle='--', label='Server Capacity (10 req/s)')
ax.fill_between([spike_start, spike_end], 0, 25, alpha=0.3, color='red', label='Spike')
ax.axvline(x=step1, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step2, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step3, color='green', linestyle=':', alpha=0.7)
ax.set_xlabel('Time (s)')
ax.set_ylabel('Rate (req/s)')
ax.set_title('External Load Profile')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.set_ylim(0, 25)
# Queue depth
ax = axes[1]
q_times = [t for (t, _) in result.queue_depth_data.values]
q_depths = [v for (_, v) in result.queue_depth_data.values]
ax.plot(q_times, q_depths, 'b-', linewidth=1)
ax.fill_between([spike_start, spike_end], 0, max(q_depths) if q_depths else 10, alpha=0.3, color='red')
ax.axvline(x=step1, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step2, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step3, color='green', linestyle=':', alpha=0.7)
ax.set_xlabel('Time (s)')
ax.set_ylabel('Queue Depth')
ax.set_title('Queue Depth Over Time')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
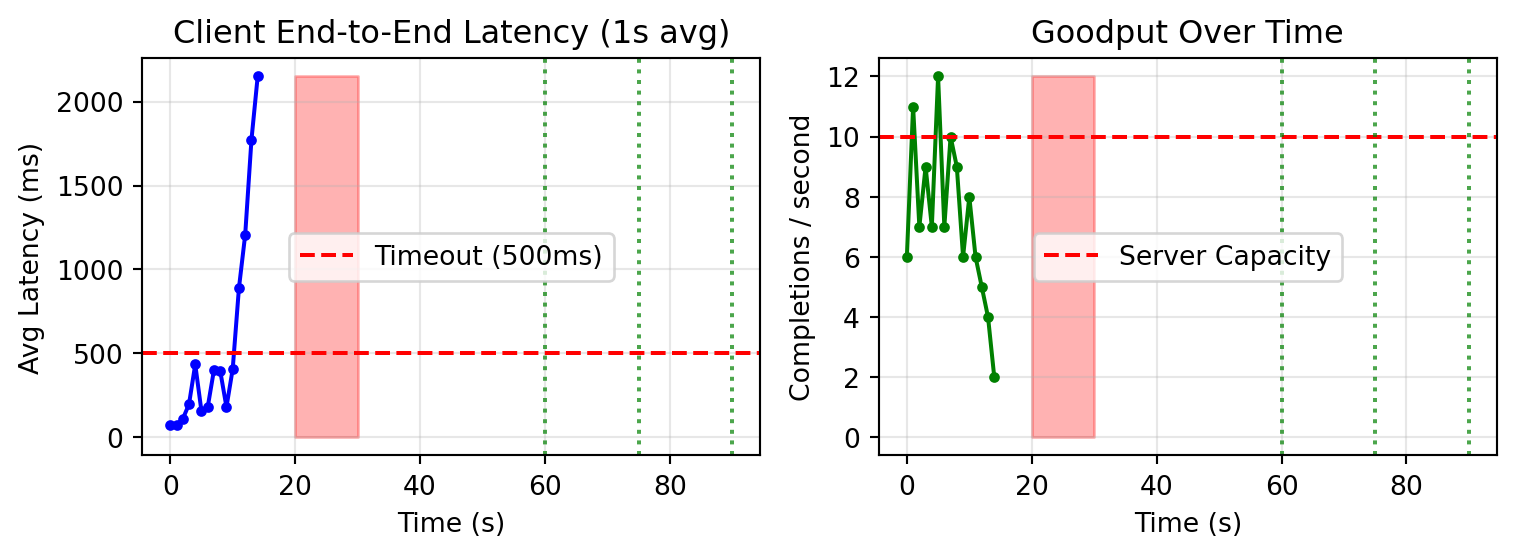
### Latency and Goodput
```{python}
#| echo: false
fig, axes = plt.subplots(1, 2, figsize=(8, 3))
# Latency
ax = axes[0]
client_times_s, client_latencies_s = client.latency_time_series_seconds()
latency_buckets: dict[int, list[float]] = defaultdict(list)
for t, lat in zip(client_times_s, client_latencies_s):
bucket = int(t)
latency_buckets[bucket].append(lat)
bucket_times = sorted(latency_buckets.keys())
bucket_avg_latencies = [sum(latency_buckets[b]) / len(latency_buckets[b]) * 1000 for b in bucket_times]
ax.plot(bucket_times, bucket_avg_latencies, 'b-', linewidth=1.5, marker='o', markersize=3)
ax.axhline(y=client.timeout_s * 1000, color='r', linestyle='--', label=f'Timeout ({client.timeout_s * 1000:.0f}ms)')
ax.fill_between([spike_start, spike_end], 0, max(bucket_avg_latencies) if bucket_avg_latencies else 1000, alpha=0.3, color='red')
ax.axvline(x=step1, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step2, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step3, color='green', linestyle=':', alpha=0.7)
ax.set_xlabel('Time (s)')
ax.set_ylabel('Avg Latency (ms)')
ax.set_title('Client End-to-End Latency (1s avg)')
ax.legend()
ax.grid(True, alpha=0.3)
# Goodput
ax = axes[1]
goodput_times, goodput_counts = client.goodput_time_series(bucket_size_s=1.0)
ax.plot(goodput_times, goodput_counts, 'g-', linewidth=1.5, marker='o', markersize=3)
ax.axhline(y=10, color='r', linestyle='--', label='Server Capacity')
ax.fill_between([spike_start, spike_end], 0, max(goodput_counts) if goodput_counts else 10, alpha=0.3, color='red')
ax.axvline(x=step1, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step2, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step3, color='green', linestyle=':', alpha=0.7)
ax.set_xlabel('Time (s)')
ax.set_ylabel('Completions / second')
ax.set_title('Goodput Over Time')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
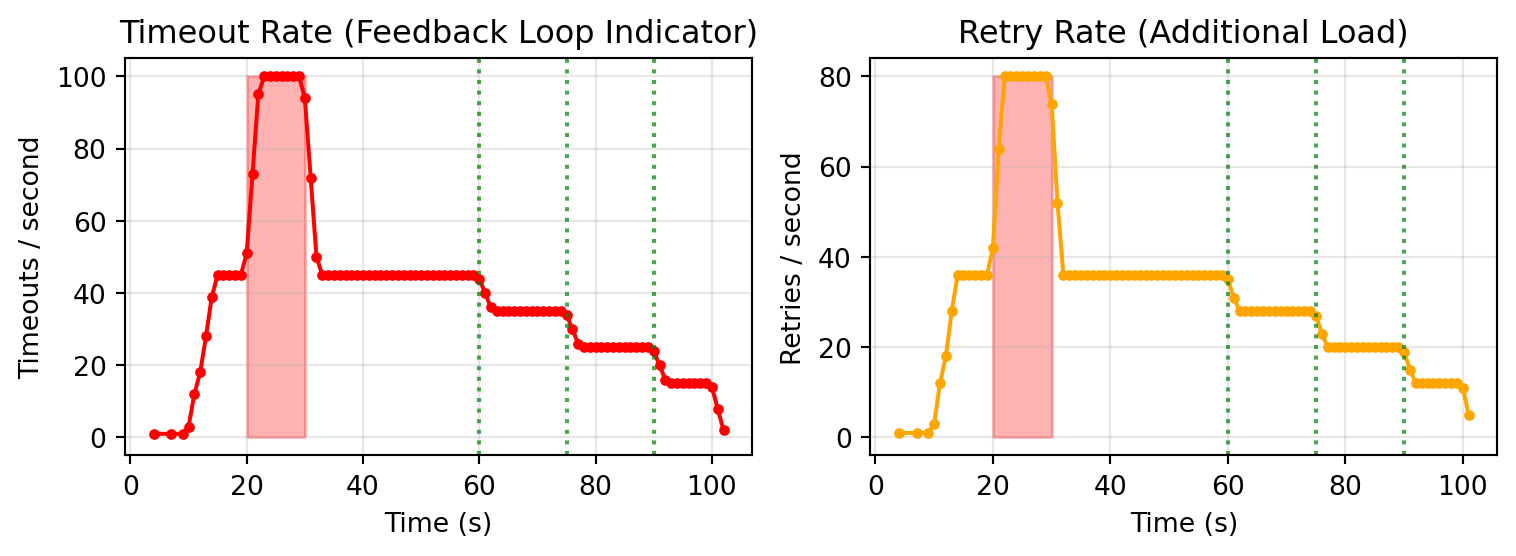
### Timeouts and Retries (Feedback Loop)
```{python}
#| echo: false
fig, axes = plt.subplots(1, 2, figsize=(8, 3))
# Timeouts
ax = axes[0]
timeout_times, timeout_counts = client.timeout_time_series(bucket_size_s=1.0)
ax.plot(timeout_times, timeout_counts, 'r-', linewidth=1.5, marker='o', markersize=3)
ax.fill_between([spike_start, spike_end], 0, max(timeout_counts) if timeout_counts else 10, alpha=0.3, color='red')
ax.axvline(x=step1, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step2, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step3, color='green', linestyle=':', alpha=0.7)
ax.set_xlabel('Time (s)')
ax.set_ylabel('Timeouts / second')
ax.set_title('Timeout Rate (Feedback Loop Indicator)')
ax.grid(True, alpha=0.3)
# Retries
ax = axes[1]
retry_times, retry_counts = client.retry_time_series(bucket_size_s=1.0)
ax.plot(retry_times, retry_counts, 'orange', linewidth=1.5, marker='o', markersize=3)
ax.fill_between([spike_start, spike_end], 0, max(retry_counts) if retry_counts else 10, alpha=0.3, color='red')
ax.axvline(x=step1, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step2, color='green', linestyle=':', alpha=0.7)
ax.axvline(x=step3, color='green', linestyle=':', alpha=0.7)
ax.set_xlabel('Time (s)')
ax.set_ylabel('Retries / second')
ax.set_title('Retry Rate (Additional Load)')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
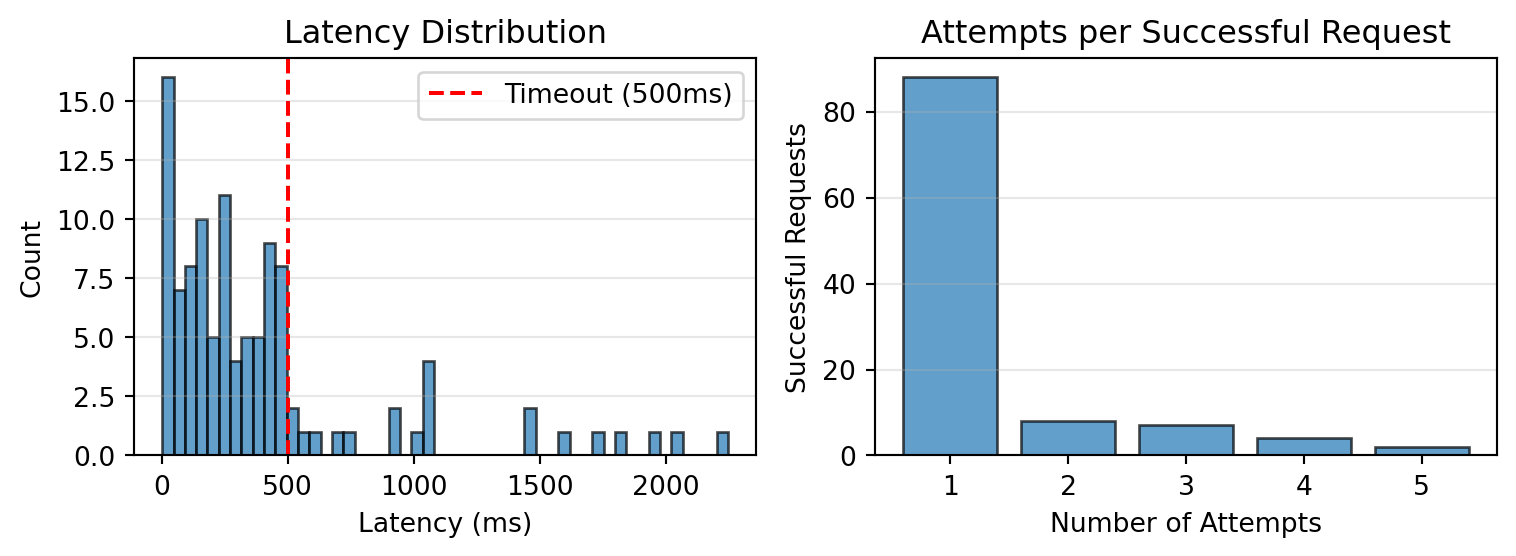
### Distributions
```{python}
#| echo: false
fig, axes = plt.subplots(1, 2, figsize=(8, 3))
# Latency distribution
ax = axes[0]
ax.hist([lat * 1000 for lat in client_latencies_s], bins=50, edgecolor='black', alpha=0.7)
ax.axvline(x=client.timeout_s * 1000, color='r', linestyle='--', label=f'Timeout ({client.timeout_s * 1000:.0f}ms)')
ax.set_xlabel('Latency (ms)')
ax.set_ylabel('Count')
ax.set_title('Latency Distribution')
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
# Attempts per request
ax = axes[1]
attempt_counts = defaultdict(int)
for attempts in client.attempts_per_request:
attempt_counts[attempts] += 1
attempts_list = sorted(attempt_counts.keys())
counts = [attempt_counts[a] for a in attempts_list]
ax.bar(attempts_list, counts, edgecolor='black', alpha=0.7)
ax.set_xlabel('Number of Attempts')
ax.set_ylabel('Successful Requests')
ax.set_title('Attempts per Successful Request')
if attempts_list:
ax.set_xticks(attempts_list)
ax.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.show()
```
## Summary Statistics
```{python}
#| echo: false
print("=" * 60)
print("METASTABLE FAILURE SIMULATION RESULTS")
print("=" * 60)
print(f"\nConfiguration:")
print(f" Server capacity: 10 req/s (mean service time = 100ms)")
print(f" Client timeout: {client.timeout_s * 1000:.0f}ms")
print(f" Max retries: {client.max_retries}")
print(f"\nLoad Profile:")
print(f" Moderate load: {profile.moderate_rate} req/s ({profile.moderate_rate/10*100:.0f}% utilization)")
print(f" Spike load: {profile.spike_rate} req/s ({profile.spike_rate/10*100:.0f}% utilization)")
print(f" Step-down rates: {profile.step_down_1_rate}, {profile.step_down_2_rate}, {profile.step_down_3_rate} req/s")
print(f"\nRequest Flow:")
print(f" External requests generated: {result.requests_generated}")
print(f" Total attempts sent to server: {client.stats_attempts_sent}")
print(f" Server processed: {server.stats_processed}")
print(f" Successful completions: {client.stats_completions}")
print(f" Timeouts: {client.stats_timeouts}")
print(f" Retries: {client.stats_retries}")
print(f" Gave up (max retries): {client.stats_gave_up}")
if client.stats_attempts_sent > 0:
retry_amplification = client.stats_attempts_sent / result.requests_generated
timeout_rate = client.stats_timeouts / client.stats_attempts_sent
print(f"\nKey Metrics:")
print(f" Retry amplification: {retry_amplification:.2f}x")
print(f" Overall timeout rate: {timeout_rate * 100:.1f}%")
q_times = [t for (t, _) in result.queue_depth_data.values]
q_depths = [v for (_, v) in result.queue_depth_data.values]
def avg_depth_in_range(start: float, end: float) -> float:
depths = [d for t, d in zip(q_times, q_depths) if start <= t < end]
return sum(depths) / len(depths) if depths else 0.0
print(f"\nQueue Depth by Phase:")
print(f" Pre-spike (10-20s): {avg_depth_in_range(10, 20):.1f}")
print(f" During spike (20-30s): {avg_depth_in_range(20, 30):.1f}")
print(f" Post-spike at 9 req/s (35-60s): {avg_depth_in_range(35, 60):.1f}")
print(f" Step-down 1 - 7 req/s (60-75s): {avg_depth_in_range(60, 75):.1f}")
print(f" Step-down 2 - 5 req/s (75-90s): {avg_depth_in_range(75, 90):.1f}")
print(f" Step-down 3 - 3 req/s (90-100s): {avg_depth_in_range(90, 100):.1f}")
timeout_times_s = [t.to_seconds() for t in client.timeout_times]
def timeout_rate_in_range(start: float, end: float) -> float:
count = sum(1 for t in timeout_times_s if start <= t < end)
return count / (end - start)
print(f"\nTimeout Rate by Phase (timeouts/sec):")
print(f" Pre-spike (10-20s): {timeout_rate_in_range(10, 20):.1f}")
print(f" During spike (20-30s): {timeout_rate_in_range(20, 30):.1f}")
print(f" Post-spike at 9 req/s (35-60s): {timeout_rate_in_range(35, 60):.1f}")
print(f" Step-down 1 - 7 req/s (60-75s): {timeout_rate_in_range(60, 75):.1f}")
print(f" Step-down 2 - 5 req/s (75-90s): {timeout_rate_in_range(75, 90):.1f}")
print(f" Step-down 3 - 3 req/s (90-100s): {timeout_rate_in_range(90, 100):.1f}")
print("=" * 60)
```
## Interpretation
**Metastable failure** occurs when:
1. The spike causes queue buildup and increased latency
2. Increased latency causes timeouts
3. Timeouts trigger retries, adding MORE load
4. The retry load prevents the queue from draining
5. Even after external load drops, the system stays degraded
Look for these signs in the results:
- Queue depth remains high after spike ends
- Timeout rate stays elevated after spike
- Retry rate sustains additional load
- System only recovers at significantly reduced external load
## References
- [Metastable Failures in Distributed Systems](https://sigops.org/s/conferences/hotos/2021/papers/hotos21-s11-bronson.pdf) - Bronson et al., HotOS 2021
- [MeFi: Metastable Failure Data Set](https://arxiv.org/html/2510.03551v1#bib.bib36) - arXiv 2024
- [Research Challenges for Metastable Failures](https://sigops.org/s/conferences/hotos/2025/papers/hotos25-106.pdf) - HotOS 2025